Handbook of DID family
本篇博客文章是我学习DID(difference in differences)的记录,侧重实践性(主要是太多底层计量原理我也搞不懂)。我期望将它做成一个实用的小册子,方便与感兴趣的小伙伴交流和用时复查。作为近些年最流行的因果推断实证设计,DID的重要性已无需多言。在本文中,我将对DID的基本原理、适用情景和限制进行概述,并介绍DID的多种变体,包括交错DID、DDD、广义DID等,这其中最重要的是交错DID。同时,对于找到的各类实用软件包,也一并介绍。如发现文中的错误之处或有其他补充,请直接告诉我(联系方式见本博客“关于”页)。
本文重点参考、摘录了“连享会”网站的内容,感谢lianxh的工作!
1 标准DID
1.1 DID的基本思想 - Canonical DID
- 框架:潜在结果因果框架
- 结构:2 X 2,【处理组&对照组】 X 【处理前&处理后】,即“两组*两期”,这一结构也意味着冲击是一次推开的
- 基本假设:
- 平行趋势假设(认为事前平行使反事实也平行);
- 政策影响无溢出效应或交互效应(SUVTA);
- 无预期效应
- 处理效应同质
- 必做检验:
- 平行趋势检验
- 安慰剂检验
举个例子:
两个相距较远的城市M和N长期以来经济发展水平有相同的趋势,两地经济交流较少。从某一年起,M市成为一项减税政策的试点城市,而N市不受影响,此后,M城市的经济增速发生了变化,而N市不变。此时,政策实施后两城市的经济水平之差减去政策实施前的经济水平差,即为政策效应(差分再差分,即双重差分)。
⬇️如下图所示
- 处理效应(政策效应)TE =(C-E)-(A-B)= CD
- AD是AC的反事实,由于DE无法直接观察到,此时以AB代替
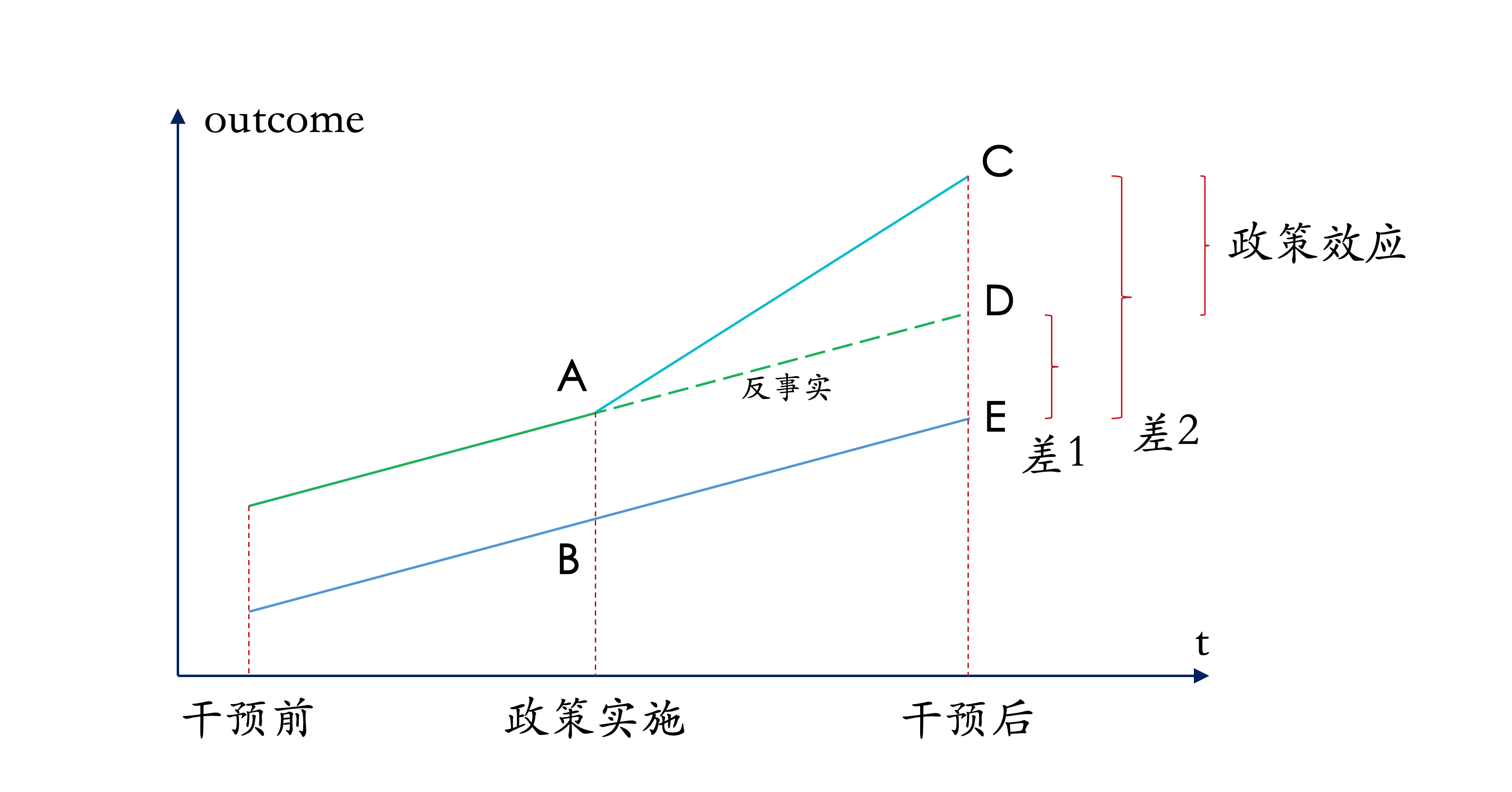
图1 双重差分法的示意
1.2 Canonical DID的标准构造
从DID的基本原理可知,DID的实验设计需包含事件冲击和时间先后,其基本构造如下: \[ y_{it} = \beta_0 + \beta_1 Treat_i + \beta_2 Post_t + \beta_3 Treat_i Post_t + \epsilon_{it} \quad(1) \] 如式(1)所示,\(yit\)为结果变量,\(Treat_i\)是事件冲击虚拟变量,\(Post_t\)是时间虚拟变量,\(\beta_3\)是我们关注的变量,为处理效应。该式的图解如图2所示
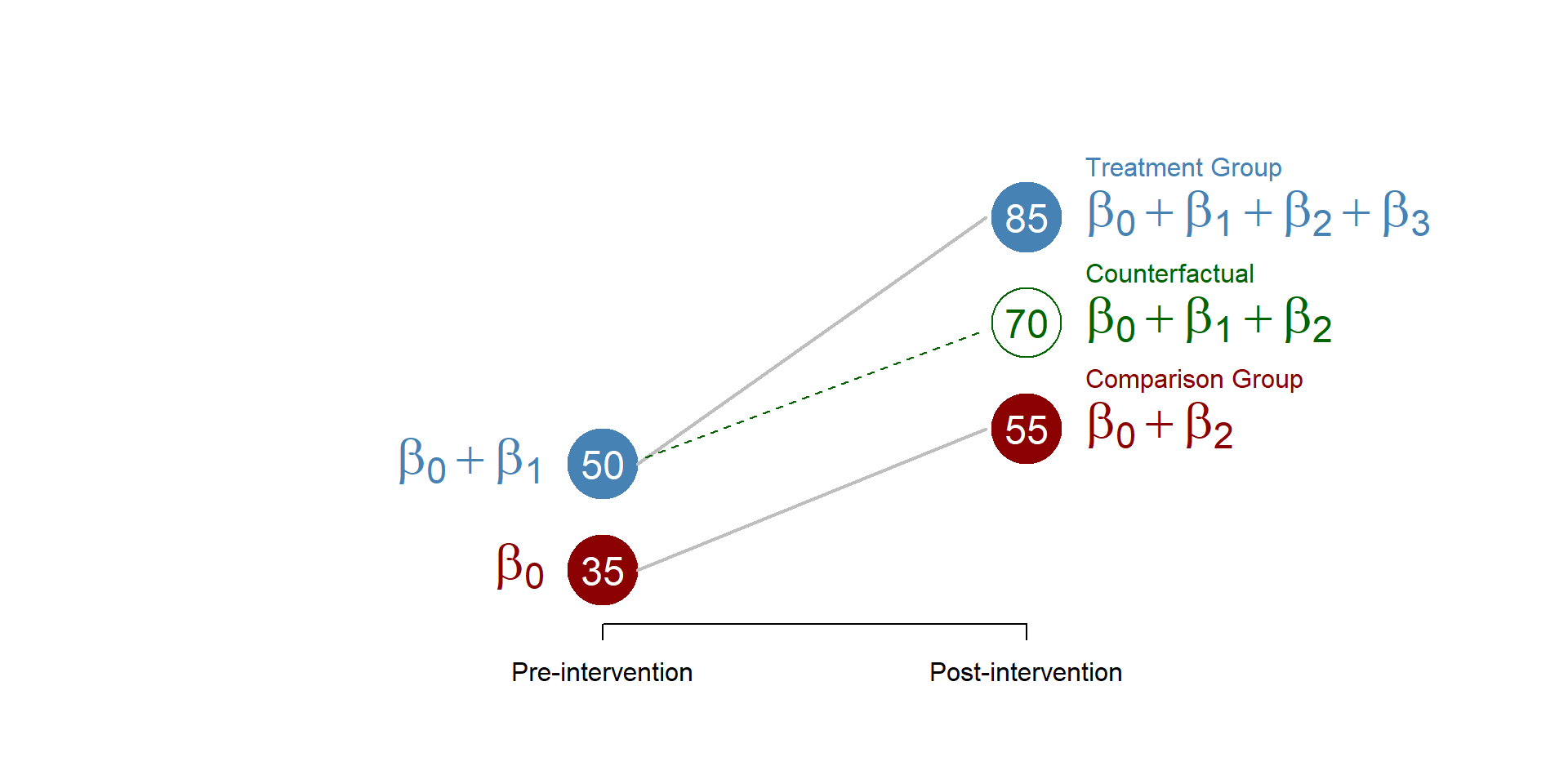
图2 DID系数的含义
表1 2X2 DID的系数释义
| Treatment = 0 | Treatment = 1 | Difference | |
|---|---|---|---|
| Post = 0 | \[ \beta_0 \] | \[ \beta_0 + \beta_1 \] | \[ \beta_1 \] |
| Post = 1 | \[\beta_0 + \beta_2\] | \[ \beta_0 + \beta_1 + \beta_2 + \beta_3 \] | \[ \beta_1 + \beta_3 \] |
| Difference | \[ \beta_2 \] | \[ \beta_2 + \beta_3 \] | \[ \beta_3 \] |
1.3 DID的数据结构
1.3.1 政策效果不随时间变化
对于第一个个体,y在第五期接受干预,出现上升,此后趋势不变。
其实不论政策效果随不随时间变化,计算的处理效应都是平均处理效应ATE。
| id | year | y | d | t | dt |
|---|---|---|---|---|---|
| 1 | 1 | 3 | 1 | 0 | 0 |
| 1 | 2 | 4 | 1 | 0 | 0 |
| 1 | 3 | 5 | 1 | 0 | 0 |
| 1 | 4 | 6 | 1 | 0 | 0 |
| 1 | 5 | 10 | 1 | 1 | 1 |
| 1 | 6 | 11 | 1 | 1 | 1 |
| 1 | 7 | 12 | 1 | 1 | 1 |
| 1 | 8 | 13 | 1 | 1 | 1 |
| 2 | 1 | 1 | 0 | 0 | 0 |
| 2 | 2 | 2 | 0 | 0 | 0 |
| 2 | 3 | 3 | 0 | 0 | 0 |
| 2 | 4 | 4 | 0 | 0 | 0 |
| 2 | 5 | 5 | 0 | 1 | 0 |
| 2 | 6 | 6 | 0 | 1 | 0 |
| 2 | 7 | 7 | 0 | 1 | 0 |
| 2 | 8 | 8 | 0 | 1 | 0 |
1.3.2 政策效果随时间变化
对于第一个个体,y在第五期接受干预,出现上升,此后趋势逐渐增强。
| id | year | y | d | t | dt |
|---|---|---|---|---|---|
| 1 | 1 | 3 | 1 | 0 | 0 |
| 1 | 2 | 4 | 1 | 0 | 0 |
| 1 | 3 | 5 | 1 | 0 | 0 |
| 1 | 4 | 6 | 1 | 0 | 0 |
| 1 | 5 | 8 | 1 | 1 | 1 |
| 1 | 6 | 11 | 1 | 1 | 1 |
| 1 | 7 | 15 | 1 | 1 | 1 |
| 1 | 8 | 20 | 1 | 1 | 1 |
| 2 | 1 | 1 | 0 | 0 | 0 |
| 2 | 2 | 2 | 0 | 0 | 0 |
| 2 | 3 | 3 | 0 | 0 | 0 |
| 2 | 4 | 4 | 0 | 0 | 0 |
| 2 | 5 | 5 | 0 | 1 | 0 |
| 2 | 6 | 6 | 0 | 1 | 0 |
| 2 | 7 | 7 | 0 | 1 | 0 |
| 2 | 8 | 8 | 0 | 1 | 0 |
1.4 计算处理效应
在Stata中有多种命令可以计算处理效应,早期的有diff,reg、areg、xtreg也可以,实证中使用较多的是reghdfe,该命令的优点是处理速度快、输出结果简洁,在各大top刊中常见。
从Stata17开始,官方提供了DID命令,分别是didregress和xtdidregress,其中后者适用于面板数据。官方命令的优点是方便回归后绘制时间趋势图。
命令的使用及介绍见文末代码。
1.5 平行趋势检验
事前平行趋势对于基于准实验设计的因果推断方法至关重要,因为事前的平行趋势是使得观测不到的反事实平行于对照组的最重要条件。
平行趋势检验一般有画时间趋势图和事件研究法(Event study)两种。
1.5.1 时间趋势图
画时间趋势图是一个比较粗糙的方法,大致看看处理组和控制组在冲击前后的趋势变化,如果是一个好的实验设计,事件冲击前处理组和控制组的均值应该有平行趋势,冲击后处理组的趋势发生变化。
绘制时间趋势图的命令可以基于xtdidreg实现,也可以手动计算。
1.5.2 事件研究法
DID是双重差分,事件研究是单次差分,在DID中运用事件研究有两个好处:
- 一是可以利用回归方法对双重差分法中最重要的平行趋势假设进行检验,与画时间趋势图相比,好处在于可以控制协变量的影响,方程形式也更加灵活;
- 二是可以更加清楚地得到政策效果在时间维度上的变化。因此,这部分检验在论文中也往往被称为政策的动态效果(Dynamic Effects) 或者灵活的 DID (Flexible DID Estimates)。
注意:此处涉及到基准期的选择,一般选择drop掉第一期或者政策前一期。
1.6 安慰剂检验
关于「安慰剂效应」,维基百科的解释如下:
安慰剂效应 (placebo effect),又名伪药效应、假药效应、代设剂效应,是指病人虽然获得无效的治疗,但却让其 “预料” 或 “相信” 治疗有效,而让病患症状得到舒缓的现象。
随着「因果推断方法」在实证研究中的使用比例不断提升,越来越多的文章也会进行安慰剂检验。其检验基本原理与医学中的安慰剂类似,即使用「假的政策发生时间或实验组」进行分析,以检验能否得到政策效应。如果依然得到了政策效应,则表明基准回归中的政策效应并不可靠。进一步,经济结果可能是由其他不可观测因素导致的,而非关注的政策所产生。
在实证研究中,无论是稳健性检验,还是安慰剂检验,亦或是异质性分析,其背后真实的目的只有两方面:
- 第一,使得文章故事性更强,逻辑更加严密;
- 第二,为因果推断服务,让读者相信研究对象之间的因果效应。
当然,不同的因果推断方法有着不同的安慰剂检验方法,这也进一步说明安慰剂检验是为因果推断服务的。而无论是哪一种因果推断方法,其对应的安慰剂检验思想均可理解为「构造伪政策」。但是,在应用安慰剂检验时,需要注意的是,不能为了安慰剂检验而进行安慰剂检验,其背后一定要有理论的逻辑。
例如,在使用 DID 方法后,通过随机构造实验组,并模拟 10000 次,然后将系数或 \(t\)值在一张图中绘制出来,以告诉读者前文的识别是可靠的。
基于 2x2 DID的基本要素(处理组、对照组、事前、事后),一个直观的思路是让这些要素发生随机偏离,来实现安慰剂检验。由此,常见的安慰剂检验方法有:
- 改变政策发生时间
采用政策发生之前的数据。将政策实施前的除第一年之外的所有年份“人为地”设定成为处理组的政策实施年份,然后根据DID模型逐年回归。当所有回归中的交互项系数都不显著时,说明通过了安慰剂检验,表明之前识别的政策平均效应是可靠的,否则就是不可靠的。如果政策实施前有n年数据,那么就要做n-1次上述回归。(其实就是将政策发生事件随机改为政策发生之前的年份)
- 随机生成实验组
通过随机抽取实验组,重复多次,提取安慰剂结果系数或 \(t\) 值,然后将其绘制在图中,并观察真实的政策效应与安慰剂结果。当真实的政策效应与安慰剂检验结果显著不同时,可排除其他随机因素对结果的干扰。
- 替换样本
替换样本进行安慰剂检验与随机生成实验组的方法较为相似。不同之处在于,随机生成实验组的安慰剂检验方法最终结果以图形展示,而替换样本安慰剂检验结果多以表格形式展示。在实际操作过程中,替换样本安慰剂检验不需要重复模拟,这在技术上显得容易一点,但在理论逻辑上更加严谨。比如,某政策颁布后,受政策影响的是污染行业,在因果识别后,可对非污染行业进行分析,探究是否存在政策效应 (亦或对政策范围外的污染行业进行分析)。如果对于非污染行业依然存在所谓的政策效应,那么前文的分析并不可靠。
- 替换变量
替换变量进行安慰剂检验主要分为替换被解释变量和替换解释变量。与稳健性检验有所不同的是,稳健性检验希望在替换变量后结果依然稳健,而安慰剂检验希望替换变量后结果不再显著。首先,替换被解释变量。某项政策实施后,对特定经济活动会产生影响,但并不是对所有的经济活动都会产生影响。因此,将被解释变量替换为预期不会受到政策影响的变量进行安慰剂检验,以排除其他可能的干扰因素。
关于平行趋势检验和安慰剂检验的更多资料,参见:
1.7 固定效应注意事项
基本控制的是个体固定效应和时间固定效应,有时会控制更高维度的交互项。
转自群聊:
关于不同维度固定效应意义的总结:
A.针对面板数据,我们通常采用固定效应来减轻不可观测因素对结果的影响。其中一维固定效应是常见的方法,包括但不限于:
个体固定效应:通过排除个体层面不受时间变化影响的不可观测因素(例如,个人性别、公司CEO特征),以减少其可能对结果造成的影响。
日期固定效应:用以缓解那些不随个体变化但会随着时间变化而发生变化的不可观测因素对估计结果的影响,比如节假日因素等。
B.随后,我们逐步将固定效应的维度提升至二维。例如:
个体-日期固定效应:用以控制个体层面随时间变化的不可观测因素对结果的影响,也就是这些不可观测因素同时随着个体和日期而变化。
行业-日期固定效应:用以控制行业层面随时间变化的不可观测因素对结果变量的影响,比如行业层面逐年变化的行业竞争程度。
省份-日期固定效应:用以控制省份层面随时间变化的不可观测因素对结果的影响,比如省份层面逐年变化的经济波动(不同省份不同年份肯定不同)。
例如,以省份-日期固定效应为例,通过控制这组固定效应,我们能够从同一年同一个省内不同地级市之间获取关键解释变量系数δ的变异。这样识别出来的δ相比不控制这一组固定效应时更为准确,可以参考Wang(2013)在研究我国开发区经济效果的文章。
*当然,省份-年份固定效应就是用省份和年份一起来分组的,无论企业变动与否,都能完全分组,那么省份-年份可以以表出省份,也可以表出年份,所以控制了省份-年份就不用再控制省份和年份。这意味着,一旦控制了省份-年份固定效应,就不再需要额外控制省份固定效应、年份固定效应。如果将省份-年份虚拟变量纳入模型后,再加入年份虚拟变量,会导致冗余,从而被自动剔除。同样,如果将省份虚拟变量加入模型,也会面临相同的情况。
下面三维固定效应也是同样的道理。
C.当前,我们正逐渐升级固定效应的维度,从二维逐步拓展至三维甚至更多维度。在模型中引入了高维度的固定效应:
城市-年份-周固定效应:用以控制城市层面随时间变化的不可观测因素,从而减轻那些随城市变化同时也会随时间变化(包括年、月和周)的不可观测因素对结果的影响。值得特别注意的是,相较于城市-年份-月份固定效应,城市-年份-周固定效应控制了更高阶的城市时变不可观测因素,因此通常是我们首选的固定效应。
城市-行业-年份固定效应:用以控制那些随着城市和行业变动,同时也会随着时间进行变化的不可观测因素对结果的影响。
这些高维度固定效应的引入使得我们能够更全面地理解并控制潜在的影响因素,从而提高模型的准确性和可靠性。
2 DID家族
Canonical DID有很多假设,现实情况中,这些假设常常无法得到满足,如事前不平行、政策不是一次性推开等。在Canonical DID的基本假设被放松的情况下,采取各种策略实现合理估计,便诞生了各种DID变体。
参见:
- 知否知否?——双重差分法(DID)“大家族”的成员们
- 黄炜,张子尧,刘安然.从双重差分法到事件研究法[J].产业经济评论,2022(02):17-36.
2.1 三重差分 DDD
基本原理:给标准DID再找一组对照组,不要求一个DID满足组内平行趋势,但要求两组DID的组内差异满足组间平行趋势;
为什么要用DDD:
政策冲击在标准DID的组内可能存在溢出效应
跨组找对照样本,但对照样本不满足平行趋势
举个例子:假设研究对象是美国的两个州,处理州(T)引入了一项医疗保健改革,而控制州(C)没有。此外,这两个州的人口可以细分为两组,A组和B组。我们打算研究的医疗保健措施只被引入B组,即B组是可以从该措施中受益的群体。最后,时间跨度上假设为两期,即保健措施实施前和实施后。
直接比较处理状态下的A组和B组似乎很方便。但如果医疗改革在处理州内存在溢出效应(B组溢出到A组),那所得结果就无法取信。另一个可能的选择是比较处理州的B组和控制州的B组。但,如果不同的州有不同的经济状况,那么无论医疗措施如何,处理州B组与控制州B组的趋势总是不同的,这种做法也就不成立。
然而,一种合理地假设是,一般的经济状况差别不会影响A组和B组人群间的相对差别。在这种情况下,我们就可以用相对差别来估计处理州中A组和B组(差异)的反事实结果。
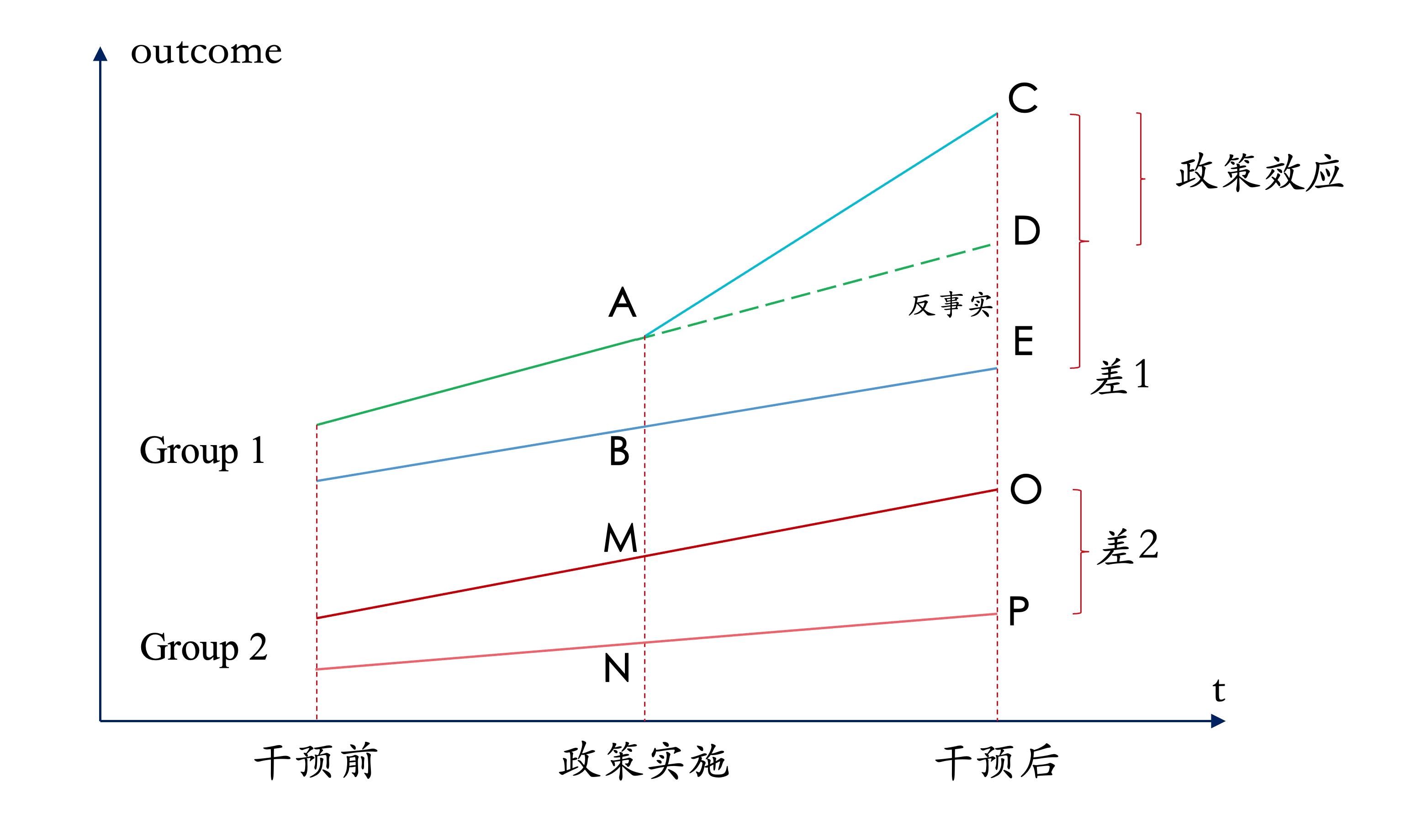
图3 三重差分法的图示
- 处理效应(政策效应)TE =(C-E)-(D-E)= (C-E)-(O-P)= CD
- 此时,DE是AB差在干预后的反事实,由于DE无法直接观察到,此时以OP代替
\[ y_{it} = \beta_0 + \beta_1 P_{i} + \beta_2 C_{j} + \beta_3 T_t + \beta_4 (P_i T_t) + \beta_5 (C_j T_t) + \beta_6 (P_i C_j) + \beta_7 (P_i C_j T_t) + \epsilon_{it}\quad(2) \]
相比DID,DDD额外增加了一个Group,变量设置也是01变量,此时,如式(2)所示,\(\beta_7\)是处理效应。
在纯对照的Group(\(C=0\))⬇️:
| T = 0 | T = 1 | Difference | |
|---|---|---|---|
| P = 0 | \[ \beta_0 \] | \[ \beta_0 + \beta_3 \] | \[ \beta_3 \] |
| P = 1 | \[ \beta_0 + \beta_1 \] | \[ \beta_0 + \beta_1 + \beta_3 + \beta_4 \] | \[ \beta_3 + \beta_4 \] |
| Difference | \[ \beta_1 \] | \[ \beta_1 + \beta_4 \] | \[ \beta_4 \] |
在有实验的Group中(\(C=1\))⬇️
| T = 0 | T = 1 | Difference | |
|---|---|---|---|
| P = 0 | \[ \beta_0 + \beta_2 \] | \[ \beta_0 + \beta_2 + \beta_3 + \beta_5 \] | \[ \beta_3 + \beta_5 \] |
| P = 1 | \[ \beta_0 + \beta_1 + \beta_2 + \beta_6 \] | \[ \beta_0 + \beta_1 + \beta_2 + \beta_3 + \beta_4 + \beta_5 + \beta_6 + \beta_7 \] | \[ \beta_3 + \beta_4 + \beta_5 + \beta_7 \] |
| Difference | \[ \beta_1 + \beta_6 \] | \[ \beta_1 + \beta_4 + \beta_6 + \beta_7 \] | \[ \beta_4 + \beta_7 \] |
将两者做差即可以得到处理效应 \(\beta_7\) ⬇️
| T = 0 | T = 1 | Difference | |
|---|---|---|---|
| P = 0 | \[ \beta_2 \] | \[ \beta_2 + \beta_5 \] | \[ \beta_5 \] |
| P = 1 | \[ \beta_2 + \beta_6 \] | \[ \beta_2 + \beta_5 + \beta_6 + \beta_7 \] | \[ \beta_5 + \beta_7 \] |
| Difference | \[ \beta_6 \] | \[ \beta_6 + \beta_7 \] | \[ \beta_7 \] |
注:标准DDD也可用双向固定效应TWFE。参见:The Twoway Fixed Effects (TWFE) model
其他资料:

2.2 交错DID (Staggered DID)
亦称多期DID、多时点DID、渐进DID、时变DID、异时DID,是目前应用非常广泛的DID变体,非常重要。相比标准DID,staggered DID放宽了政策冲击在同一时间影响处理组的条件。
标准双重差分法模型和双向固定效应双重差分法模型涉 及的政策实施时点或冲击发生时点为同一时期。然而,现实生活中诸多政策实施未必发生在某一时点,而是先有试点再逐步推广,在渐进的过程中推而行之,如增值税转型、土地确权、新农保实施、 高铁开通、官员晋升等。交错双重差分法为处理这类情形提供了方法。(黄炜等,2022) \[ Y_{it} = \beta_0 + \beta_1 * Treat_{it} + \beta * \Sigma Z_{it} + \mu_i + \tau_t + \epsilon_{it}\quad(3) \] Staggered DID一般化模型设定见式(3),\(\beta_1\)是政策效应的大小,相比标准DID,Staggered DID使用一个随时间和个体变化的处理变量代替了交互项(其实就是将标准DID中的交互项写成一个变量)。
Staggered DID的数据结构如下:
1 | |
图示⬇️(刘冲等,2022)
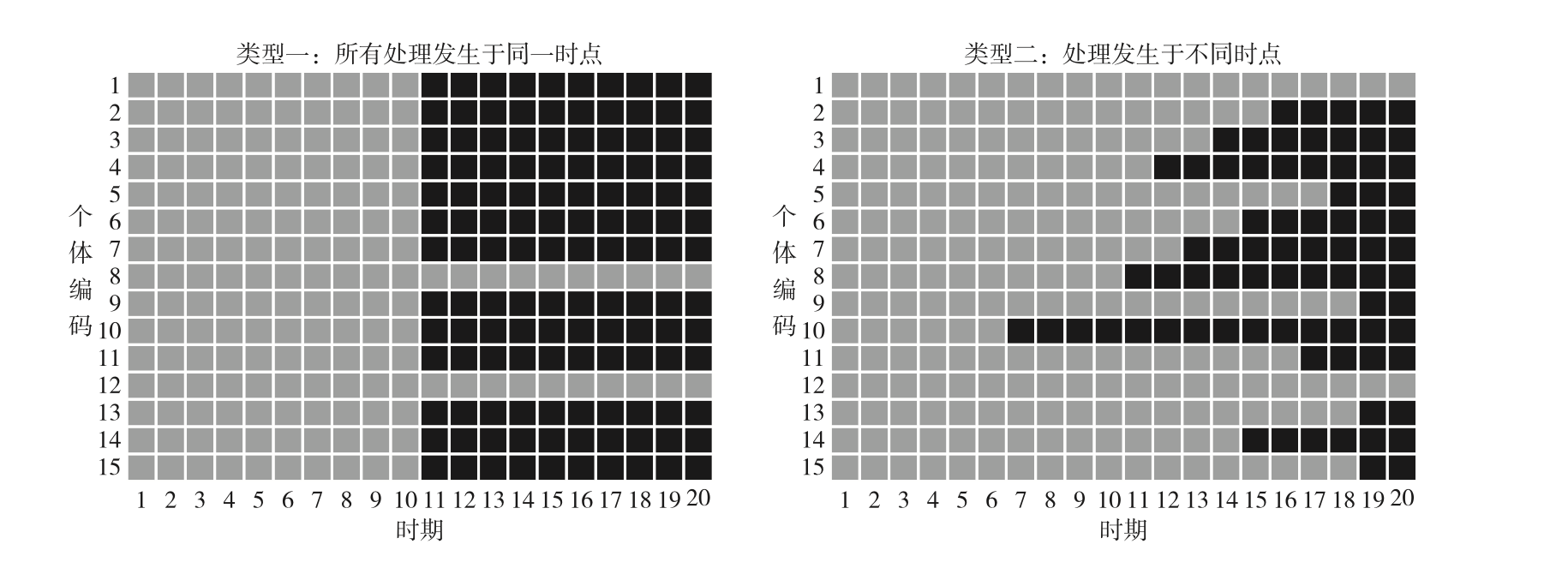
Staggered DID可以使用 panelview命令进行可视化,参见Stata绘图:面板数据可视化-panelview
或 【视频号29】用panelview可视化交叠DID
。
有关Staggered DID的Stata模拟和处理,参见:
- 倍分法DID详解 (二):多时点 DID (渐进DID)
- 倍分法DID详解 (三):多时点 DID (渐进DID) 的进一步分析
- Big Bad Banks:多期 DID 经典论文介绍
- Stata:多期倍分法 (DID) 详解及其图示
- 多期DID:平行趋势检验图示
- 多时点DID保姆级教程(上)-平行趋势检验
- 多时点DID保姆级教程(下)-安慰剂检验
- 【计量】交叠DID实用教程 or 分享: 交叠DID简明使用教程, 降低学者DID的学习成本!
- Stata:Mundlak方法的DID-jwdid
新进展-非常重要:
计量经济学领域的最新研究成果表明,当试点政策在不同时点开展时,双向固定效应下得到的多时点DID回归估计值可能存在偏差(Goodman-Bacon, 2021),这是由处理时点差异和异质性处理效应所导致的结果。本文分别将Callaway and Sant'Anna (2022)的稳健估计方法和堆叠DID方法(Stacked Regression Approach)应用于本文的基准模型中,重新估计试点政策的平均处理效应。本文将Callaway and Sant'Anna (2022)提出的估计方法应用于本文的基准模型中,重新估计试点政策的平均处理效应。【张莉,刘昭聪,程可为等.产业用地审批改革与资源配置效率——基于微观企业土地存量数据的研究[J].中国工业经济,2023(09):61-79.DOI:10.19581/j.cnki.ciejournal.2023.09.004.】
How much should we trust staggered difference-in-differences estimates?
Difference-in-differences with variation in treatment timing
上述三篇文章发现TWFE在staggered DID中可能存在严重的问题(bacon分解 诊断),因此需要使用其他方法,如csdid、堆叠DID方法(Stacked Regression Approach)、两步回归法等。【王鹏超,韩立彬.多时点双重差分法的潜在问题与解决措施[J].东北财经大学学报,2023,No.146(02):27-39】
权威文章参见:
其他国内分析文章参见:
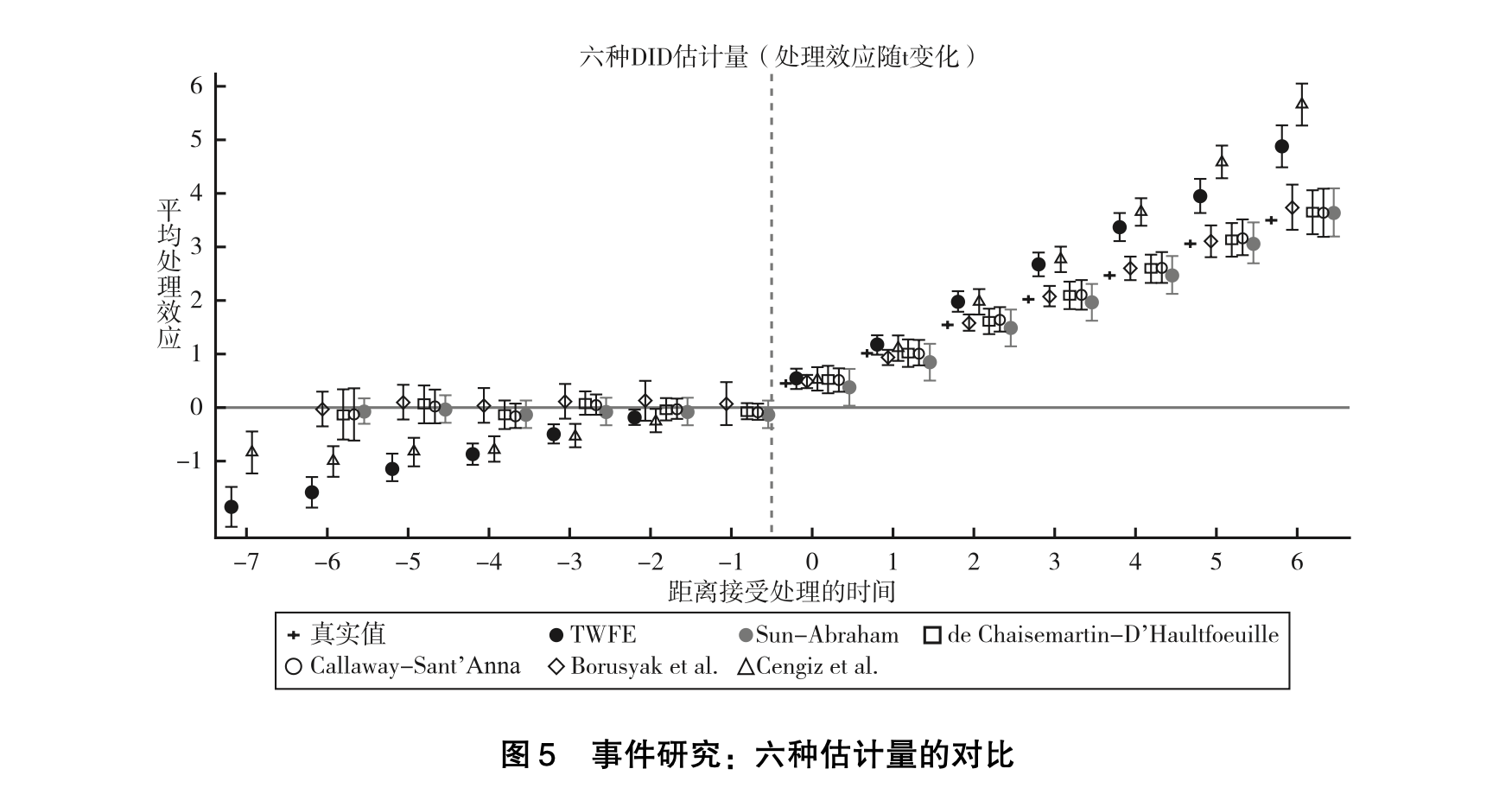
- 刘冲,沙学康,张妍.交错双重差分:处理效应异质性与估计方法选择[J].数量经济技术经济研究,2022,39(09):177-204.
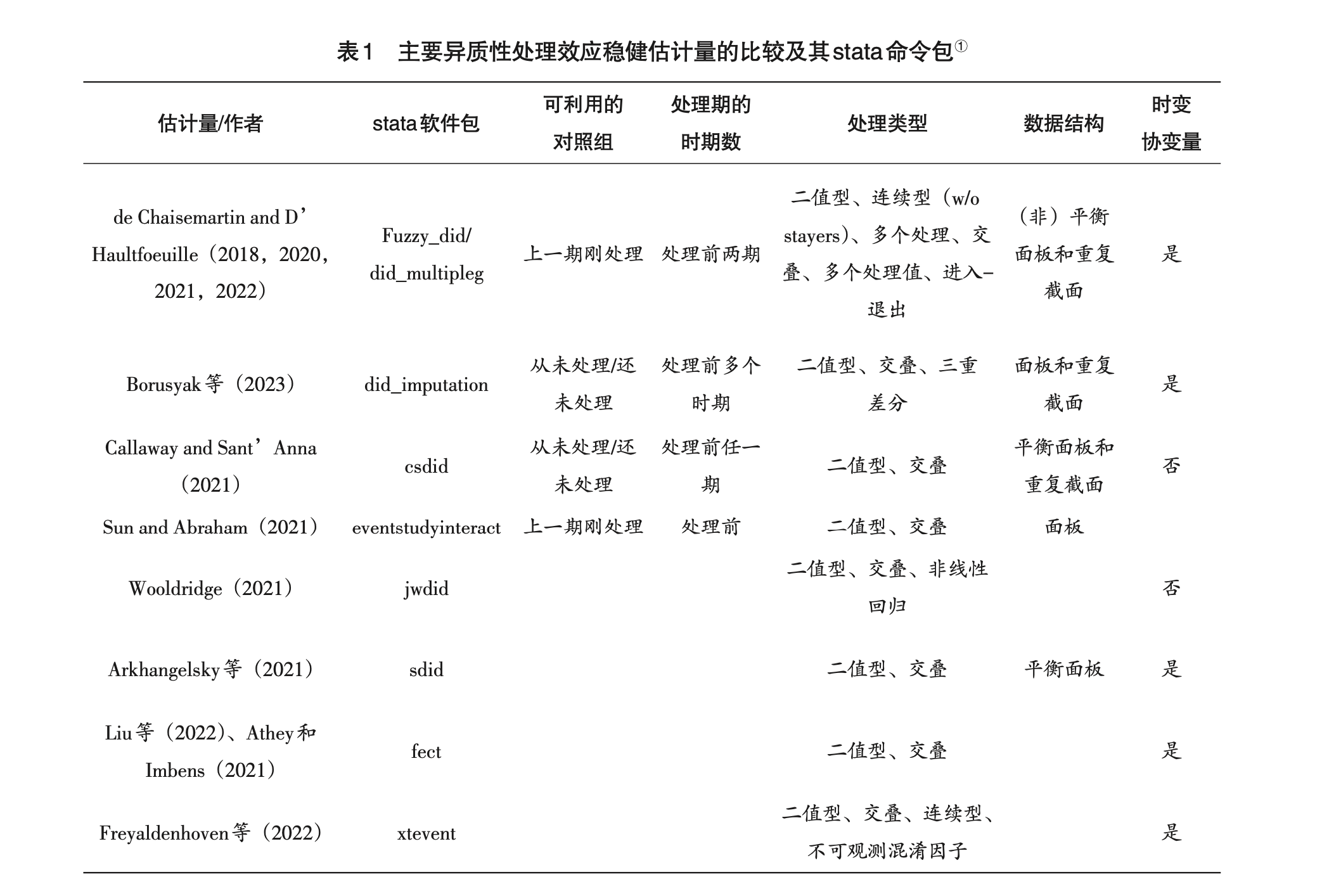
- 许文立.双重差分法的最新理论进展与经验研究新趋势[J].广东社会科学,2023(05):51-62.
- 许文立提到,在实证研究中的,对于估计偏误的诊断有五种方法:1️⃣回归法;2️⃣Bacon分解,但只适用于强平衡面板数据的情况;3️⃣CD分解法;4️⃣SA分解法;5️⃣静态效应检验。
交叠DID使用TWFE,问题出在哪里(参见:【计量】交叠DID实用教程 ):
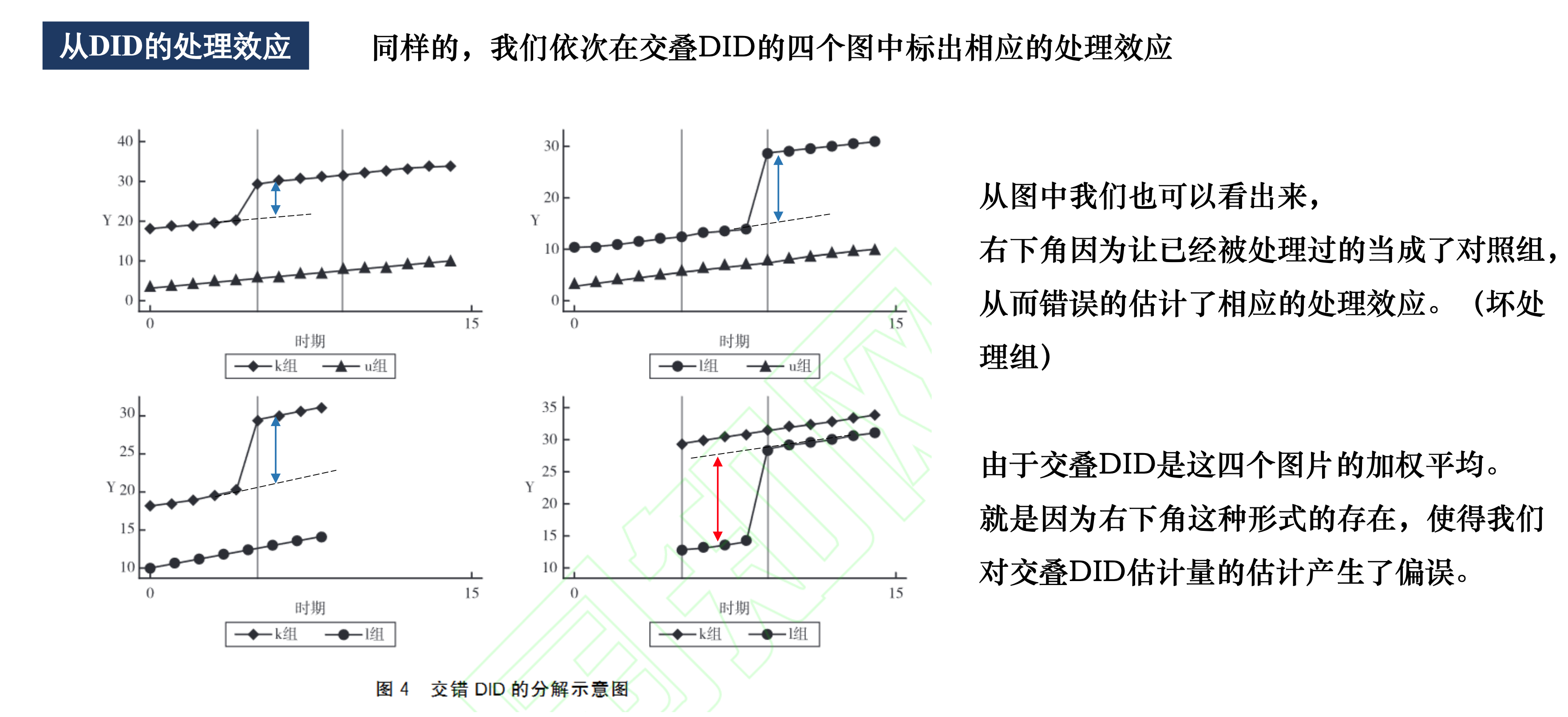
2.2.1 Bacon decomposition
标准的 DID 通常用来估计处理组与控制组在处理前后的结果差异,然而在实践中,由于处理往往发生在不同的时间点上,研究者通常使用下式估计处理效应 \(\beta^{DD}\): \[ y_{it} = \alpha_i + \alpha_t + \beta^{DD}D_{it} + e_{it}\quad(4) \] 式(4)中,\(\alpha_i\) 为截面个体效应,\(\alpha_t\) 为时间固定效应,\(D_{it}\) 为个体 \(i\) 在 \(t\) 时刻是否接受处理哑变量。但事实上,我们对于这种不同时点的处理效应理解有很大局限性,且通常依赖于 “条件于群组与时间固定效应,干预应当近似于随机分配” 的一般假定。Andrew Goodman-Bacon (2021) 提出,双向固定效应估计量 (TWFEDD) 等于数据中所有可能的两组或两期 DD 估计量的加权平均值。
其估计的因果解释需要平行趋势假设和随时间恒定的处理效应,他展示了如何分解两个规范之间的差异,并提供了对包含时变控制模型的新分析。本文将简要概述这篇文章,并介绍基于这一分解方法的
Stata 命令 bacondecomp。
Bacon decomposition是一种TWFE估计量偏误诊断的方法,可以看出TWFE在Staggered DID应用的效果。
参见:
- Bacon decomposition
- Stata:多处理时点效应估计的Bacon分解-bacondecomp
- 【视频号24】交叠DID的陷阱:从Bacon分解说起(1)
- 【视频号25】交叠DID的陷阱:从Bacon分解说起(2)
- 【应用计量系列52】再谈培根分解:新升级、新操作、新结果
- 【香樟推文2505】交叠DID偏误的诊断、解决与应用——兼论连续DID的偏误
- Bacon分解结果的解读
2.2.2 csdid
标准的 DID 模型将样本分为两组:实验组和对照组;将时间分为两个阶段:政策发生前和政策发生后。所有的实验组样本都在同一时间点受到政策冲击。
随着 DID 方法的拓展,许多实证研究将其拓展为多期 DID,即实验组并非在同一时点遭受政策冲击。但是,自 2019 年来,不少学者纷纷指出这种多期 DID 有可能会产生有偏估计 (Athey and Imbens,2022;Baker et al.,2022;Goodman-Bacon,2021)。
其主要原因在于,多期 DID 估计的本质是多个不同处理效应的加权平均,权重可能存在为负的情形。在权重为负的情下,不同处理效应加权平均后得到的平均处理效应,可能会与真实的平均处理效应方向相反。Baker et al. (2021) 通过数据模拟发现,多期 DID 估计出来有偏误的处理效应甚至会与真实处理效应的符号相反。
为此,Callaway and Sant'Anna (2021) 提出了一种用于识别异质性多期 DID 的新方法,该新方法适用于以下三种情形:
- 时间分为多期;
- 实验组受到政策冲击的时间并非同一;
- 实验组和对照组只有在控制了协变量之后才满足平行趋势假定。
csdid现在已成为Stata的程序包(也有R的版本),可以汇报Staggered
DID的稳健估计量,结果与TWFE做比较,可以看看基准回归是否合理。
参见:
2.2.3 Stacked DID
stackedev实现在 Cunningham (2021) and Baker (2021) 中讨论并在 Cengiz 等人 (2010) 中实现的堆叠事件研究估计。
该包将各个数据集或堆叠追加在一起。每个堆叠包括来自同一时间段内接受治疗的一组单位和从未接受过治疗的所有单位的所有观察结果。通过将单个治疗单位队列与从未治疗过的单位进行比较,在每个堆叠中确定效果。
这种方法避免了对后期实施单位和早期实施单位的错误比较,如果效果因治疗队列而异,则可能会偏向双向固定效应 (TWFE) 估计(Goodman-Bacon,2021年)。
堆叠事件研究分三个步骤进行估计:
- 首先,创建单个堆叠;
- 其次,它们被附加在一起;
- 最后,该软件包通过 reghdfe 估计事件研究,其中包括逐个堆叠的固定效应、逐个堆叠的时间固定效应和逐个堆叠上的标准误差聚类。
stackedev也是一个Stata软件包,可以结合下面的资料安装尝试。
参见:
- stackedev (Cengiz, Dube, Lindner, Zipperer 2019)
- 系统梳理DID最新进展: 从多期DID的潜在问题到当前主流解决方法和代码!
- 【香樟推文2435】从交叠双重差分法到堆叠双重差分法——举例与讨论
- Stata--交叠DID异质稳健估计之堆叠DID
2.2.4 did2s 两步回归法
最近一系列文献都表明,当处理组个体接受处理的时间是交错的,而且平均处理效应随着组别以及时间发生变化时,常见的双重差分估计就不能识别一个典型处理效应并做出合理的度量 (Borusyak and Jaravel, 2017; Athey and Imbens, 2018; Goodman-Bacon, 2018; de Chaisemartin and D’Haultfoeuille, 2020; Imai andKim, 2020; Sun and Abraham, 2020)。
为此,本文将介绍可能缓解上述问题的方法——两阶段双重差分。具体地,本篇推文主要分为以下内容:
- 首先,提供了一些简单的直觉来解释为什么双重差分回归不能确定 group ×× period 平均处理效应;
- 其次,提出了一个可供选择的二阶段 GMM 估计框架 (two-stage estimation framework)。在这个框架中,我们在第一阶段识别组别效应和时期效应,在移除了组别效应和时期效应之后,在第二阶段,通过比较处理组和对照组的结果差异来识别平均处理效应。两阶段方法对于被处理的时间是交错的以及处理效应具有异质性的情况下估计结果是稳健的,而且还能够用来识别许多不同的平均处理效应,方法简单直接好用;
- 最后,为了方便大家理解,我们用实例并结合 Stata
操作来演示该方法的实现,其中重点介绍
did2s命令。
参见:
2.2.5 did_multiplegt 多期多个体模型
双边固定效应多期 DID 模型假设对于样本的处理是不变的,这样的假设在现实中常常不成立。首先,处理变量可能不是一个二元变量,如不同地区的政策力度不同。其次,处理也并非是一次性的,样本不能简单地一分为二处理组和控制组,如降雨对于地区的影响,会出现从有到无、从无到有的多个交替过程,这时就需要一个动态的处理组。
动态处理组的设定放松了传统 DID 模型中处理不变的设定,可以有效解决了上述的问题。并且,在模型中处理变量 \(D\) 可以为二元变量,也可以是非二元变量。
did_multiplegt也是一个Stata命令,同时,该命令还可以处理很多其他情况,如允许个体退出实验。
参见:
2.2.6 did_imputation
did_imputation也是一个Stata命令,可以作事件研究法的稳健有效估计量,好像也可以应用于Staggered
DID?
参见:
2.2.7 eventstudyinteract
The eventstudyinteract command is written by Liyang Sun
based on the Sun and Abraham 2020 paper Estimating
Dynamic Treatment Effects in Event Studies with Heterogeneous Treatment
Effects.
The command potentially has some issues.
参见:
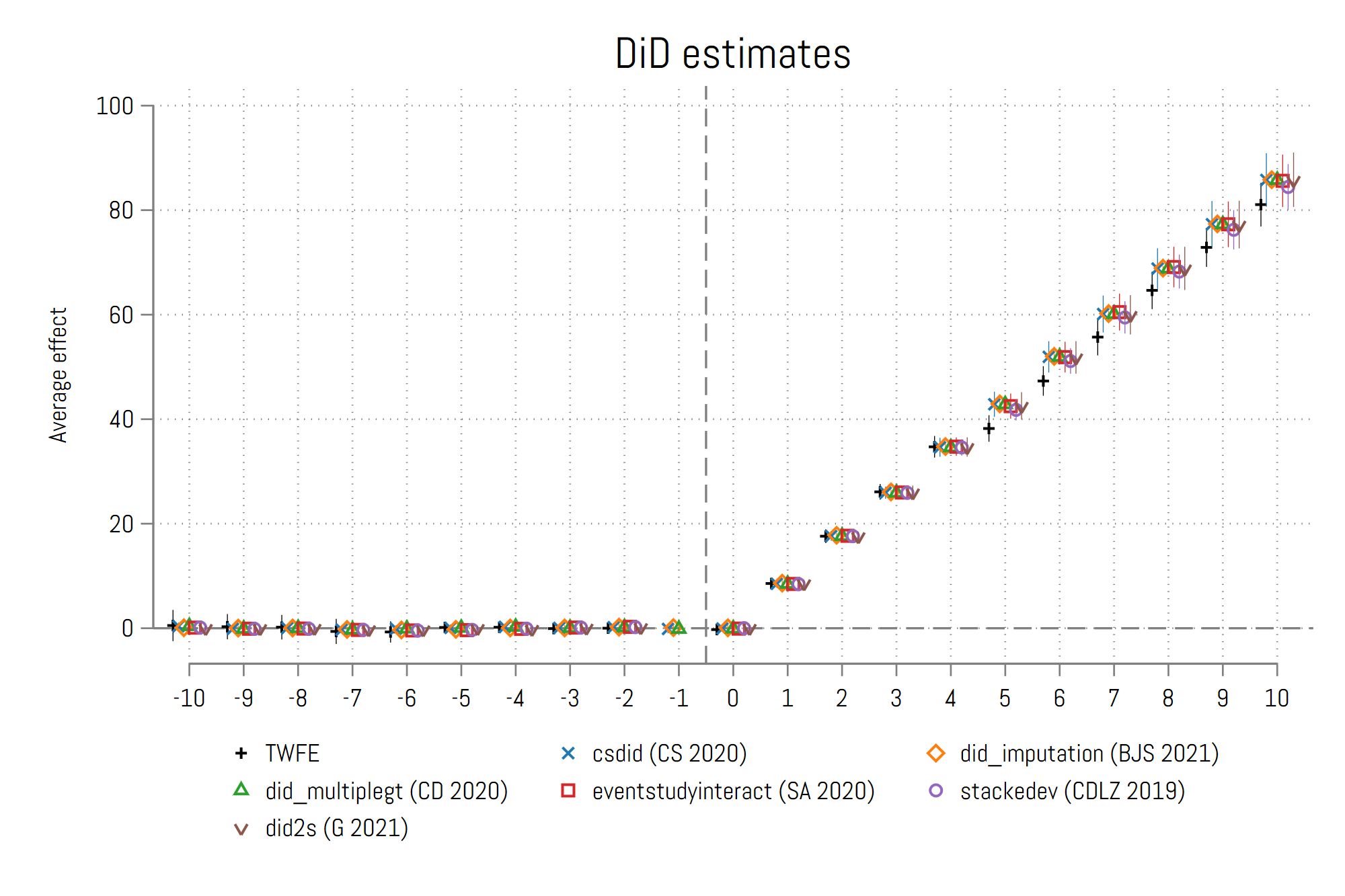
2.2.8 各种估计量的比较
就是将TWFE、did_multiplegt、csdid、did_imputation、eventstudyinteract、stackedev、did2s等方法的估计结果放一起对比。(图片来自All estimators)
许文立也做了比较:
刘冲等(2022)也做了比较,感兴趣的小伙伴也可以自行查看论文并复现。
参见:
2.3 队列DID (Cohort DID)
亦称截面DID,即使用横截面数据来评估某一历史事件对个体的长期影响。常用于评估特殊历史事件对个体和家庭的长期影响(通常使用的都是横截面数据)。与标准DID相似,队列DID也有两个维度的变异,通常而言,一个维度是地区,另一个维度是出生(年龄)队列,如果感觉难以理解的话,其实只需把出生队列这个维度理解为时间就好了。
推荐阅读:
- Chen, Y., Fan, Z., Gu, X., & Zhou, L. A. (2020). Arrival of young talent: The send-down movement and rural education in China. American Economic Review, 110(11), 3393-3430.
- Guo, S., Gao, N., & Liang, P. (2023). Winter Is Coming: Early-life Experiences and Politicians’ Decisions. The Economic Journal, uead061. (这篇文章我精读并做了复现,感觉非常厉害。)
- 疫苗接种、人力资本积累与收入增长 (Dr.Wang 的大作,《经济学(季刊)》待刊)
- 队列DID:以知识青年“上山下乡”为例-T401
- 截面数据的DID设计:Cohort DID(队列DID)的Stata使用“说明书”
2.4 广义DID (Generalized DID)
亦称强度DID、连续DID。见得不多。
当所有研究对象均或多或少同时受到了政策干预,即仅有处理组而无控制组时,仍然能够考虑应用双重差分法。对此,可以根据研究对象受到的具体冲击情况来构建处理强度(treatment intensity)指标来进行分析,此时个体维度并不是从 0 到 1 的改变,而是连续的变化。因此,可以将个体维度的政策分组虚拟变量替换为用以表示不同个体受政策影响程度的连续型变量,该种方法被称为广义双重差分法。Nunn 和 Qian(2011)研究了一个经典的例子,他们研究了土豆种植扩散对欧洲人口增长的影响。欧洲几乎所有地区都种植了土豆,不存在未种植土豆的地区,因此没有标准意义上的控制组。他们的选择是将地区间土豆种植适宜度作为处理强度,以 1700 年前后为处理时点,使用广义双重差分法估计了引入土豆对人口增长的影响。(黄炜等,2022)
推荐阅读:
2.5 模糊DID (Fuzzy DID)
在标准双重差分法等方法的应用情境中,处理组和控制组之间通常泾渭分明,因此可以通过分组差分得到较为“干净”的处理效应。但是,有时冲击并未带来急剧(sharp)变化,所谓的“处理组”中虽然受冲击率高于其他组别,但并没有完全被干预或受政策冲击,而所谓的“控制组”中也并非完全没有受到冲击,即处理组和控制组之间没有明确的分野,不存在“干净”的处理组与控制组。模糊双重差分法为处理此类情形提供了可能,de Chaisemartin 和 d’Haultfoeuille(2018)在文章中详细介绍了该种方法,并利用该方法重新评估了印度尼西亚的教育回报。(黄炜等,2022)
更多内容参见:
2.6 混合截面DID
混合截面数据与面板数据相比,其不同之处在于它的不同时点的观测个体是不同的,但是它也有时间和个体两个维度,所以只要进行巧妙的构思,依然可以构建DID模型进行政策评估。伍德里奇同志在《计量经济学导论》一书13.2节举了一个经典的例子“垃圾焚化炉的区位对住房价格的影响”(Kiel and McClain,1995),来讲解混合截面DID的做法,大家有兴趣可以去看下。(江河JH,2022)
参见:
2.7 其他情况
DID家族百花齐放,且在不断发展中,还有很多类型、策略或模式,如“进入-退出型”DID、双重机器学习、合成双重差分DID、空间DID、一刀切的DID、考虑溢出效应的DID、非线性DID(或称 NL-DID、CIC)、分位数DID、被解释变量为虚拟变量的DID,DID还可以与其他策略相结合,如PSMDID、RDD&DID!内容繁杂,但基础原理离不开标准DID,可以自行查看。
黄炜等学者认为“几乎任何两个维度的差异之差异都可以从双重差分的角度去理解。也就是说,几乎所有的交互项模型都可以理解为一种双重差分法。”更多说明可以阅读原文。
其他资料参见:
3 DID Checklist
Jonathan Roth等学者近期在Journal of Econometrics发表了一篇文章,讲述了DID的新进展,文章也是一个Handbook,列出了使用DID的待查清单。“计量经济圈”的推文里有清单的翻译版,在此摘录:
- 每个个体都在同一时间受到政策冲击吗?
- 如果是,并且面板是平衡的,则使用式 (5) 或 (7) 等双向固定效应TWFE估计方法。TWFE会产生易于解释的估计值。
- 如果不是,请考虑使用“异质性稳健估计值“来估计时间上交错执行的政策处理效应(如3节所述)。至于使用哪种方法的估计值,取决于一项政策的出现和结束情况,以及研究者打算施加的平行趋势假设。只有当你很确信政策处理效应具有同质性才使用双向固定效应TWFE估计值。
- 你确定平行趋势假设有效吗?
- 如果是,请解释有效的原因,包括回归方程所设定的函数形式的验证。如果理由是政策发生在时间上的(准)随机性,请考虑使用第6节中讨论的更有效的估计值。
- 如果不是,请按照以下步骤开展:
- 如果以协变量为条件的平行趋势假设更合理,请考虑第4.2节所述的以协变量为条件的估计值。
- 通过构建事件研究图来评估平行趋势假设的合理性。如果有一个共同的政策冲击日期,并且使用的是无条件平行趋势假设,请根据 (16) 等回归方程绘制系数。如果不是,请参阅4.3节以获取有关事件图构建的建议。
- 在汇报事件研究图时,也可以采用4.4.1节所述的方法对事前趋势进行进一步的验证。
- 如4.5节所述,报告正式的敏感性分析,描述结论对潜在违反平行趋势的稳健性。
- 你是否有大量从超总体(super-population)中通过整群抽样(cluster sampling)获得的处理组和控制组样本?
- 如果是,则在相应聚类级别上使用聚类稳健方法(cluster-robust methods)。一个经验法则,是在独立分配处理效应的级别上进行聚类(例如,政策在州级别上实行时就在州级上聚类),具体可以参见5.2节。
- 如果有少量受到政策冲击的整群样本,可以考虑使用5.1节中替代性政策效应推断方法。
- 如果你无法想象或获取超总体,请考虑5.2节中基于模型设计(design based)的政策效应推断方法。
翻译来自:
关于JoE论文的其他内容参见:
4 实用软件包
4.1 DID相关的软件包
Jonathan Roth等在JoE论文里还对DID相关的软件包进行了表格总结,包含平行趋势诊断,并带上了出处,我这里一并摘录过来。(Markdown显示的表格不美观,建议还是看原文。。。)
Table 2. Statistical packages for recent DiD methods.
| Heterogeneity Robust Estimators for Staggered Treatment Timing | ||
|---|---|---|
| Package | Software | Description |
| did, csdid | R, Stata | Implements Callaway and Sant’Anna (2021) |
| did2s | R, Stata | Implements Gardner (2021), Borusyak et al. (2021), Sun and Abraham (2021), Callaway and Sant’Anna (2021), Roth and Sant’Anna (2021) |
| didimputation, did_imputation | R, Stata | Implements Borusyak et al. (2021) |
| DIDmultiplegt, did_multiplegt | R, Stata | Implements de Chaisemartin and D’Haultfoeuille (2020) |
| eventstudyinteract | Stata | Implements Sun and Abraham (2021) |
| flexpaneldid | Stata | Implements Dettmann (2020), based on Heckman et al. (1998) |
| fixest | R | Implements Sun and Abraham (2021) |
| stackedev | Stata | Implements stacking approach in Cengiz et al. (2019) |
| staggered | R | Implements Roth and Sant’Anna (2021), Callaway and Sant’Anna (2021), and Sun and Abraham (2021) |
| xtevent | Stata | Implements Freyaldenhoven et al. (2019) |
| DiD with Covariates | ||
| Package | Software | Description |
| DRDID, drdid | R, Stata | Implements Sant’Anna and Zhao (2020) |
| Diagnostics for TWFE with Staggered Timing | ||
| Package | Software | Description |
| bacondecomp, ddtiming | R, Stata | Diagnostics from Goodman-Bacon (2021) |
| TwoWayFEWeights | R, Stata | Diagnostics from de Chaisemartin and D’Haultfoeuille (2020) |
| Diagnostic/ Sensitivity for Violations of Parallel Trends | ||
| Package | Software | Description |
| honestDiD | R, Stata | Implements Rambachan and Roth (2023) |
| pretrends | R | Diagnostics from Roth (2022) |
Note: This table lists R and Stata packages for recent DiD methods, and is based on Asjad Naqvi’s repository at https://asjadnaqvi.github.io/DiD/. Several of the packages listed under “Heterogeneity Robust Estimators” also accommodate covariates.
其实看这个Note里的博客也是可以的。
4.2 其他软件包
didplaceboStata命令,可以一键进行DID安慰剂检验 ,适用于单时点冲击的标准DID,以及多时间冲击的交叠DID(staggered DID)permuteStata命令,也可以简单进行安慰剂检验;eventddStata命令,可以一行代码绘制平行趋势图。
5 其他参考资料
(1)一个很详细的博客
https://diff.healthpolicydatascience.org/
(2)一个三四年前的博客?Data science for public service
https://ds4ps.org/PROG-EVAL-III/DiffInDiff.html
(3)一个有用的关于DID的R markdown书
https://bookdown.org/mike/data_analysis/difference-in-differences.html
(4)The effect
https://theeffectbook.net/ch-DifferenceinDifference.html
(5)The mixtape
https://mixtape.scunning.com/09-difference_in_differences
(6)一个网页,有各种DID相关的包和进展--这个非常重要
https://asjadnaqvi.github.io/DiD/
https://asjadnaqvi.github.io/DiD/docs/code
(7)因果推理的统计工具-一本很强大的R书
https://chabefer.github.io/STCI/
(8)与DID有关的一系列问题
https://friosavila.github.io/playingwithstata/index.html
(9)DID资源站,JoE文章作者、DID专家的博客,他的小狗🐶似乎很可爱
https://www.jonathandroth.com/did-resources/
(10)这个人的博客有点意思
https://christinecai.github.io/items/PublicGoods.html
6 附:DID实验代码
6.1 标准DID数据模拟、分析与检验代码
1 | |
6.2 Staggered DID数据模拟、分析与检验代码
1 | |