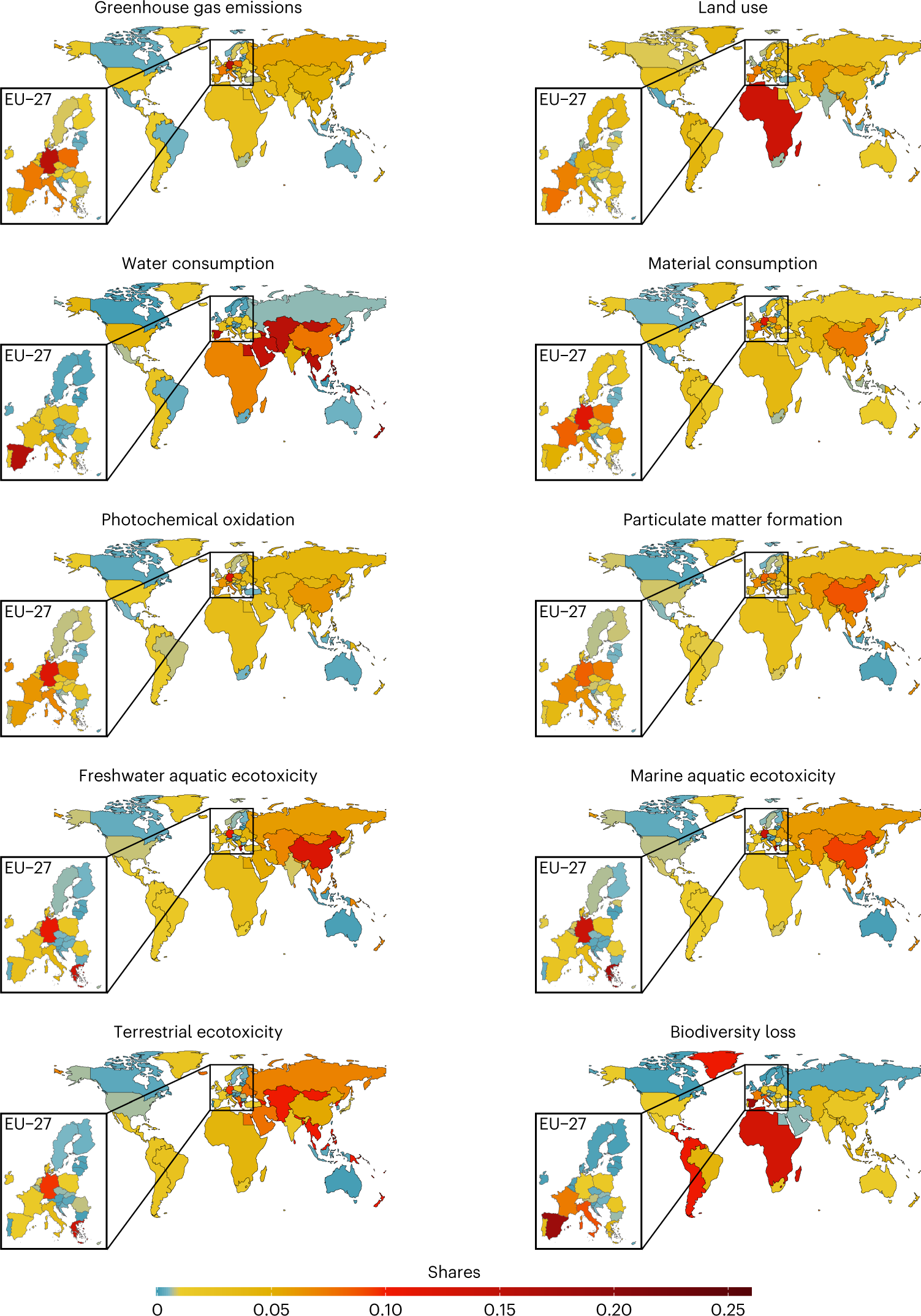
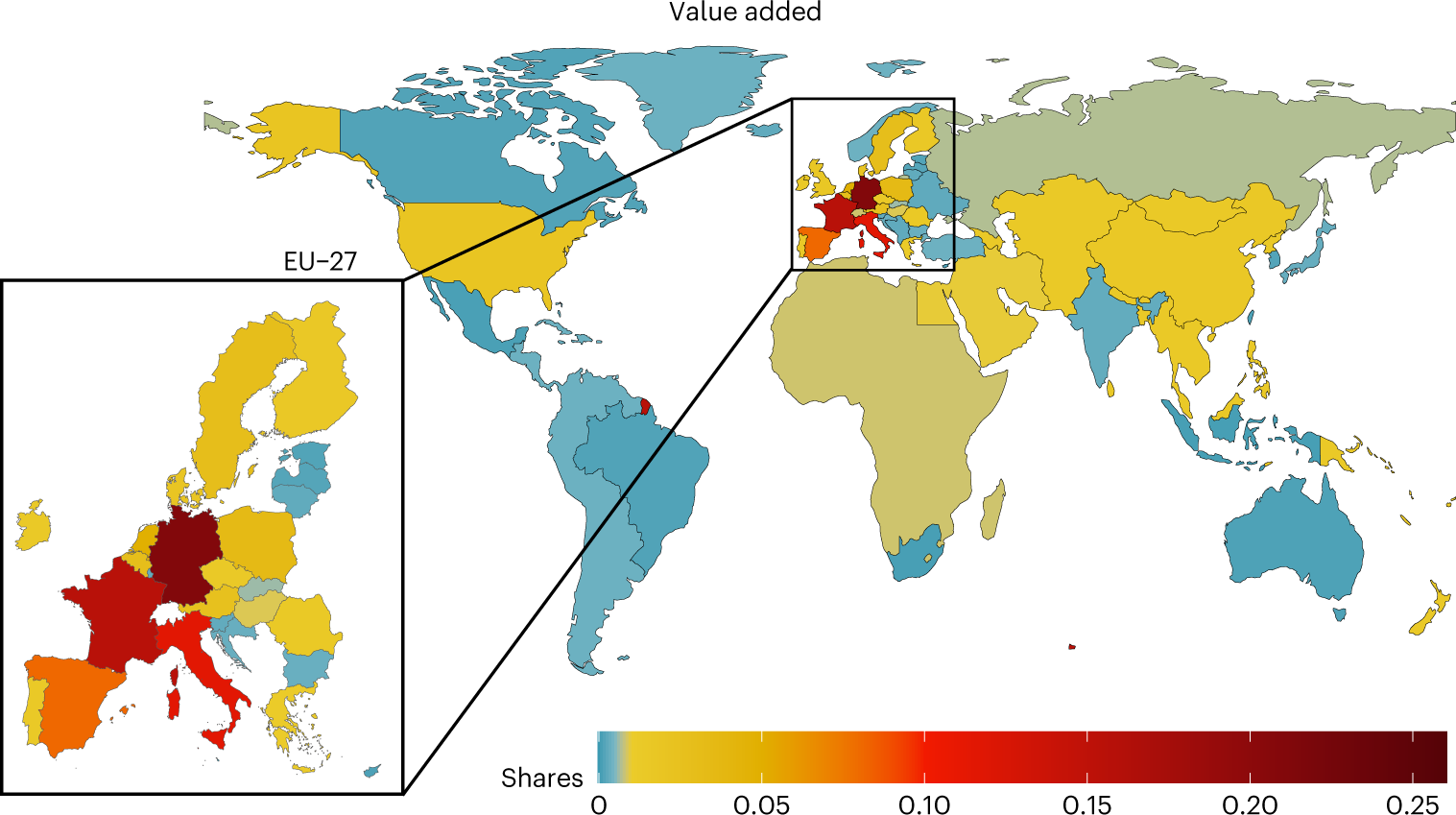
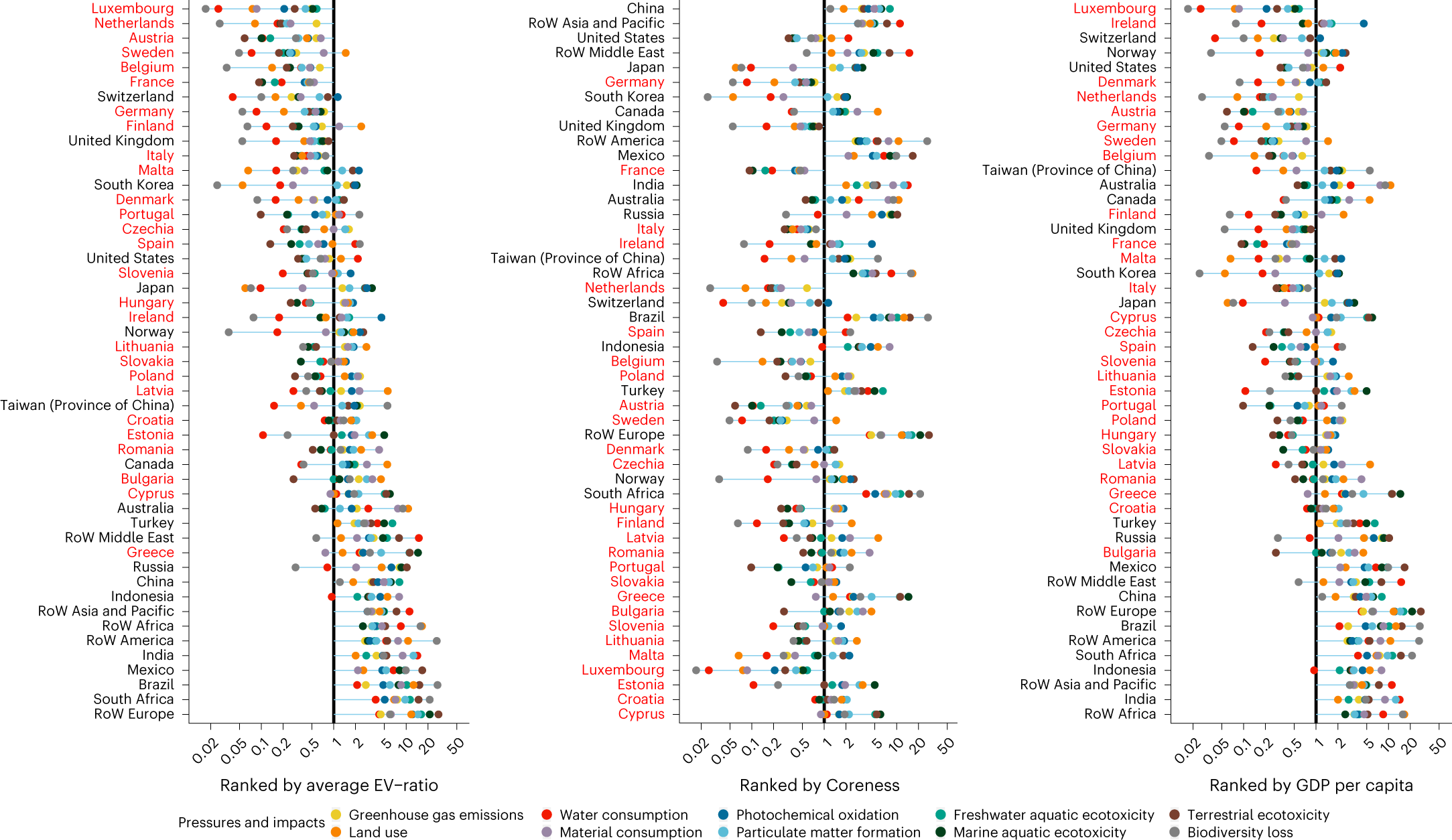
在消费发生国(在本研究中为欧盟),由于价值链末端的附加值份额较高,因此增加值往往更高。因此,欧盟内部的EV比率往往低于欧盟外部。当根据各国的人均GDP(GDPpc)进行排名时(图5,右排名),有一个普遍的模式表明,较富裕的国家往往比较贫穷的国家具有更低的EV-ratio。由于过去的研究表明,位于贸易网络核心的国家(即,它们是高度集中、一体化程度高的贸易国家的一个有凝聚力的子集团的一部分)往往经历相对较少的环境压力,我们还考虑了各国的核心度得分(有关计算核心度的更多详细信息,请参阅补充信息)。图
5 中的中间排名显示,几个核心度得分相对较高的非欧盟国家(例如,中国、RoW
亚太地区、RoW 中东、RoW 美洲和墨西哥)的 EV 比率也很高,这表明核心度和
EV
比率之间可能存在正相关关系,尽管关系较弱。(附表4不是显示负相关??)
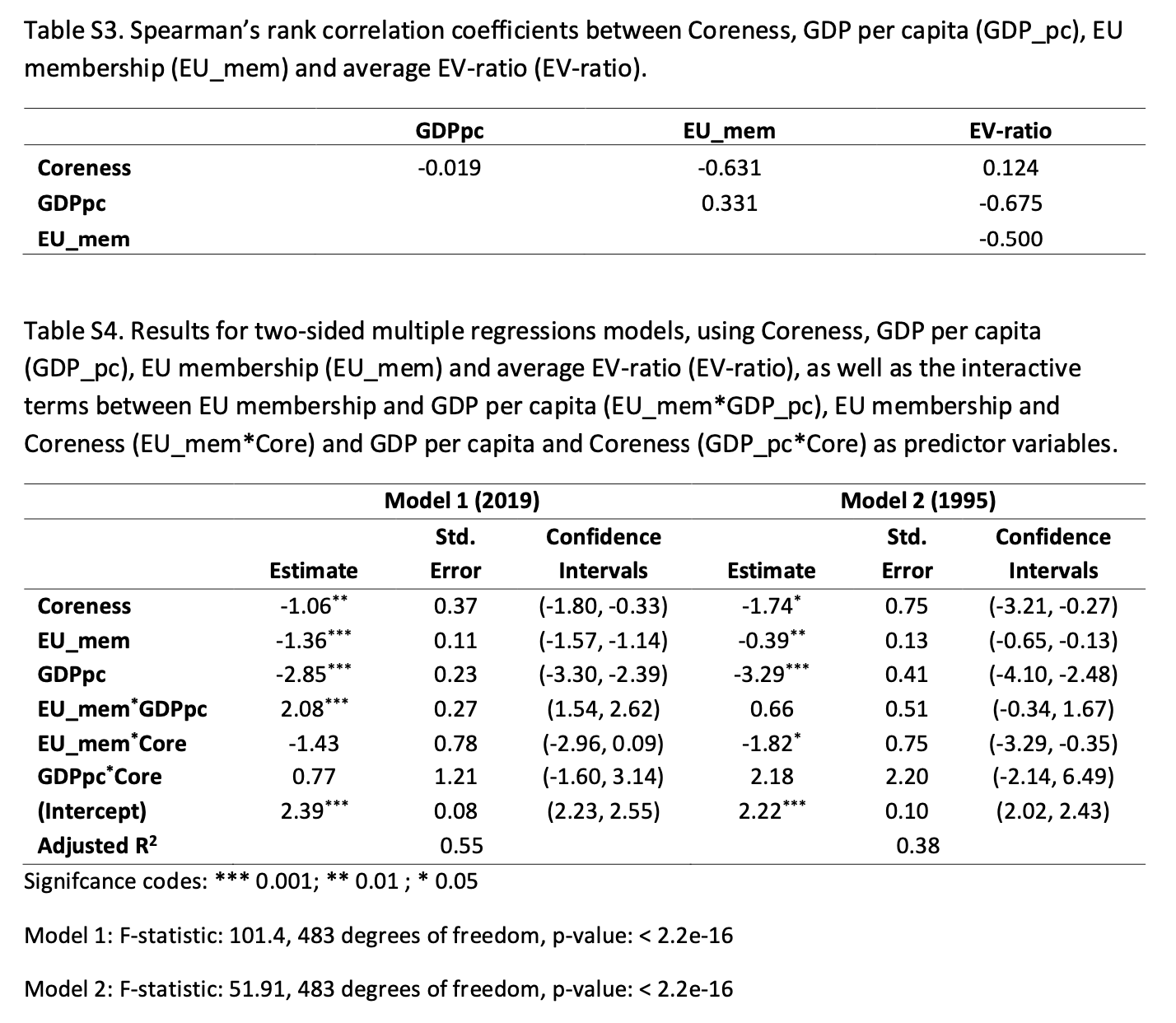
为了进一步探索这些趋势,我们对 2019
年的数据进行了多元回归分析,然后在 1995
年的数据上复制了这些分析,以探索前者的模式在后者中也可以检测到的程度。我们的模型输入核心度、GDPpc
和欧盟成员资格 (EU_mem) 作为预测 EV
比率的解释变量。这些模型结果以及这四个变量之间的相关性可以在补充表3和表4中找到。
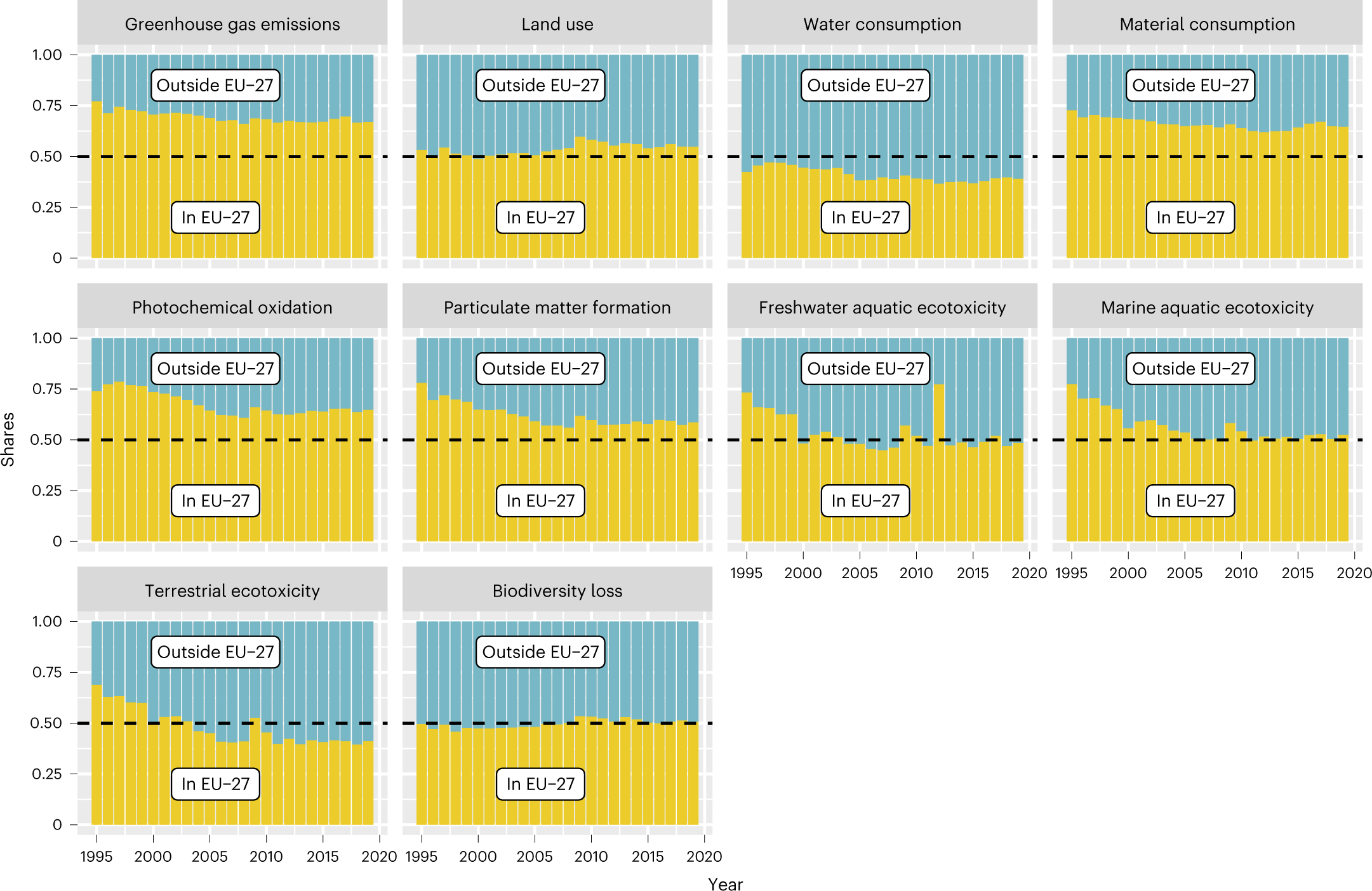
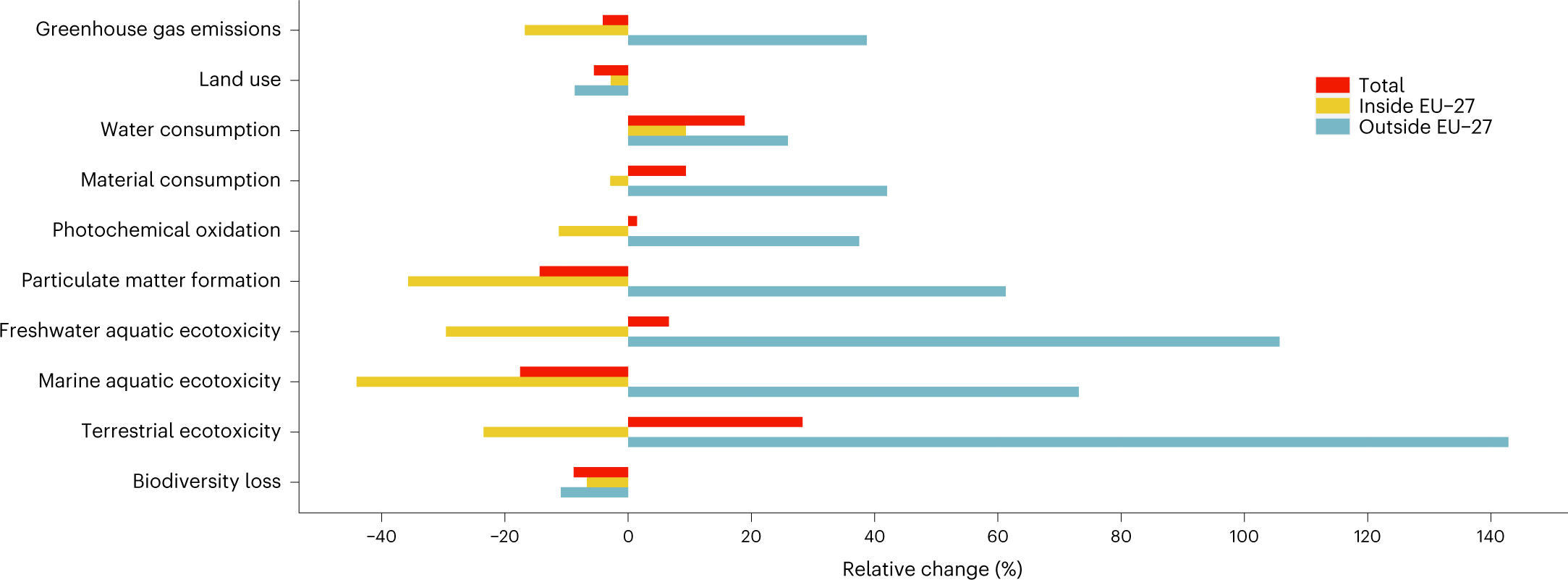
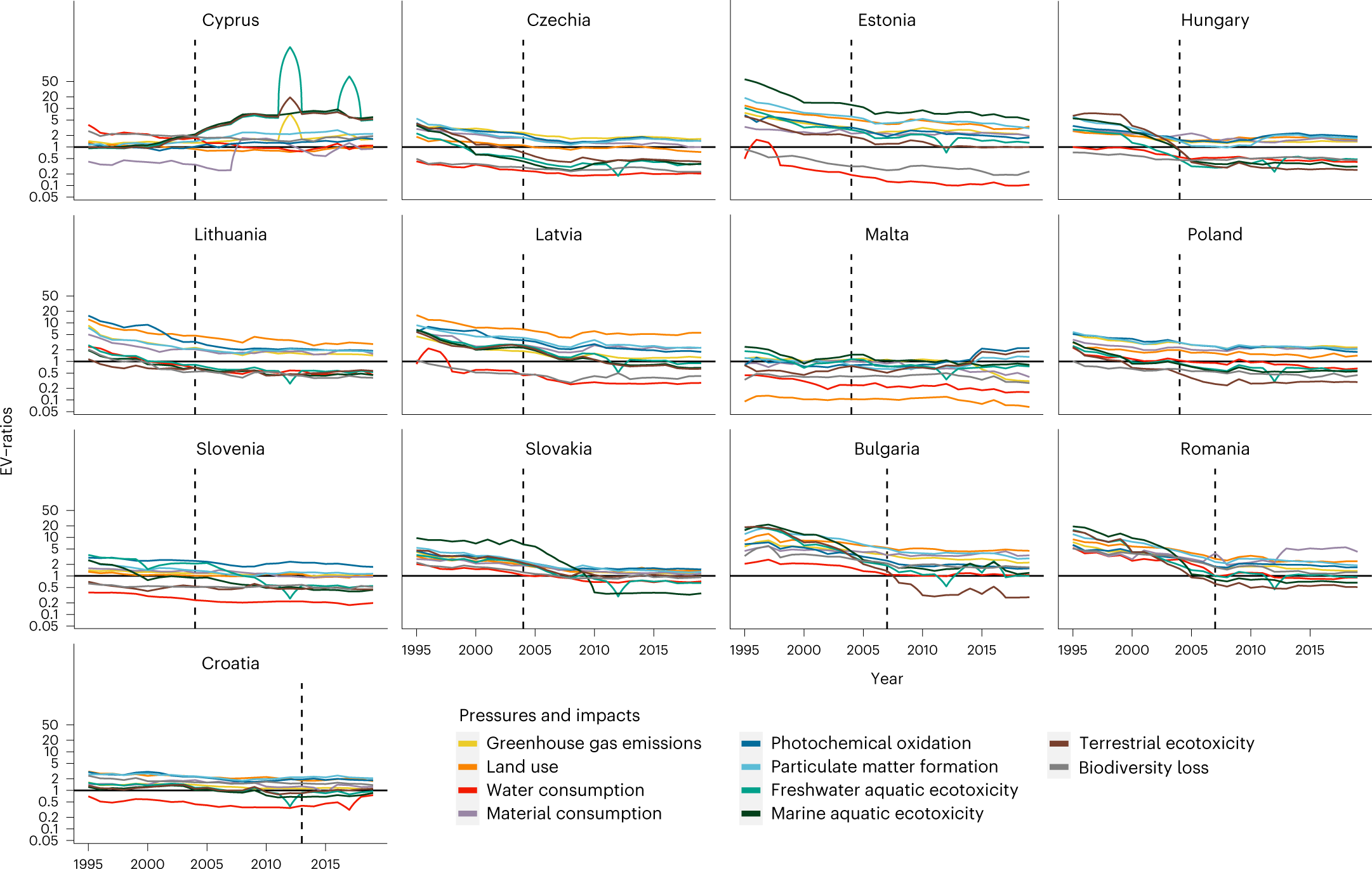
结果表明,与欧盟消费相关的EV比率对大多数成员国比对非欧盟国家和地区更有利。与此同时,欧盟的消费给RoW欧洲地区带来了比世界其他任何地方都更高的环境压力和每附加值影响。该地区包括阿尔巴尼亚、黑山或塞尔维亚等现有欧盟候选成员国以及乌克兰和摩尔多瓦等欧盟的新候选国(current
EU candidate members)。
#------------------------------------- import needed libraries -------------------------------------------------- import numpy as np import scipy.io import scipy import pandas as pd #set directory path for downloaded raw EXIOBASE 3.8.1 files Dir = "/Users/yu/Temp/Global land ESSV exchange/NS/Unequal_Exchanges_SI_Code/Data//" v1 = ['ixi','pxp']
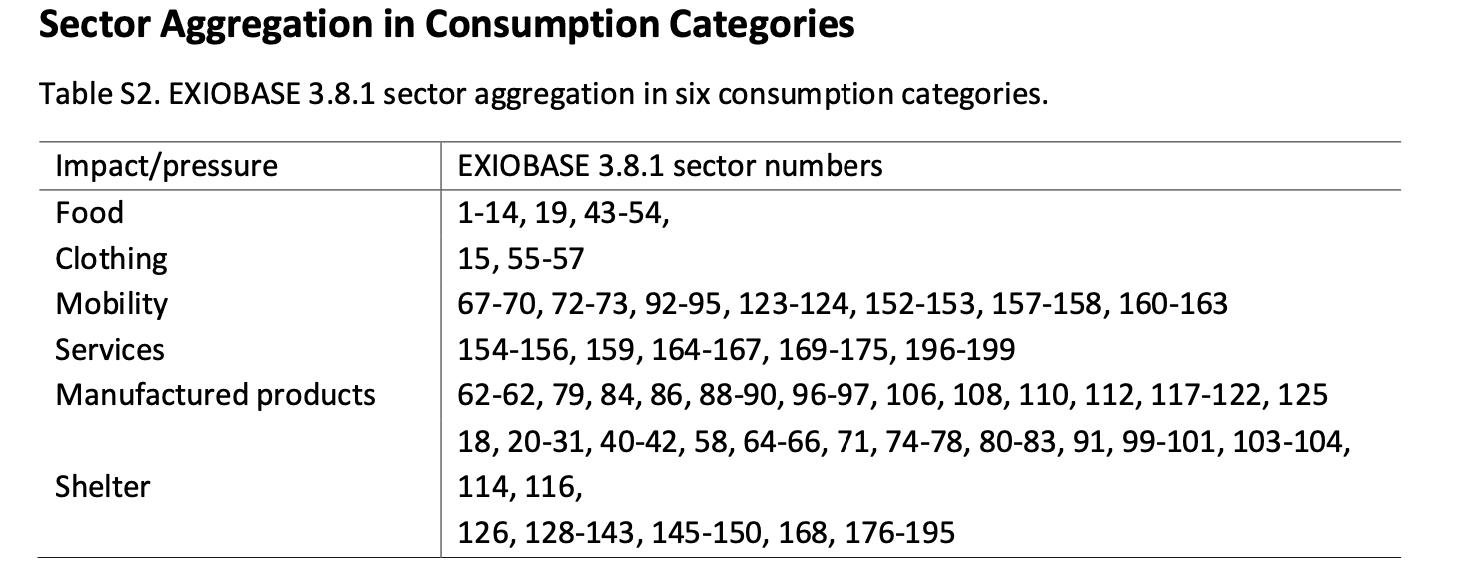
""" 关于EXIOBASE的一些说明(这里其实需要一些关于投入产出表的基础知识和EXIOBASE的结构,及其卫星账户的知识): 参考:https://onlinelibrary.wiley.com/doi/10.1111/jiec.12715 发现WIOD和EORA都更新了,WIOD更新了2000年之前的一些东西,EORA也到2022,但2016年之后的年份就是在抢钱。ICIO有1995-2018 1.数据时效:The original EXIOBASE 3 data series ends 2011. In addition, we also have estimates based on a range of auxiliary data, but mainly trade and macro-economic data which go up to 2022 when including IMF expectations. A lot of care must be taken in use of this data. It is only partially suitable for analysing trends over time! As of v3.8 (doi: 10.5281/zenodo.4277368), the end years of real data points used are: 2015 energy, 2019 all GHG (non fuel, non-CO2 are nowcasted from 2018), 2013 material, 2011 most others, land, water. More details are available in the readme file. 2.文件命名: IOT_YYYY_ixi.zip - MRIO archive for Year YYYY in industry by industry format 即部门表 IOT_YYYY_pxp.zip - MRIO archive for Year YYYY in product by product format 即产品表 (原始页面这里写错了,应该是pxp,不是ixi) 3.文件结构: The MRIO archive contains the following files: Z.txt - flow/transactions matrix 其实是个7987*7987的矩阵,不过加上了表头,可以把数据粘贴到Excel里看看 A.txt - matrix/inter-industry coefficients, (direct requirements matrix) 大小同上,A=Z/x Y.txt - final demand 有时候也叫F矩阵,最终需求矩阵,每个地区有7类最终需求,所以该部分的大小是 (7*49)*7987 x.txt - gross/total output 49*163,一共7987条,如果是pxp,就是49*200,上同 unit.txt - Units of the flow data 单位是百万欧元 两个扩展资料: satellite - uncharacterized stressors data - e.g. CO2 emissions, land use per category, etc. impacts - characterized stressors (=> impacts) - e.g. total GWP100, total land use, etc The total list of stressors and impacts are in the index of all files, most conveniently in the 'unit.txt'. Both extension subfolder contain: F.txt - Factors of productions/stressors/impacts F_Y.txt - Stressors/impacts of the final demand 列数为49*7,行数是1113,参见 unit 的第一列 S.txt - Direct stressor/impact coefficients S_Y.txt - Stressor/impact coefficients of the final demand M.txt - MRIO extension multipliers (total requirement factors of consumption) D_cba.txt - Consumption based accounts per sector D_pba.txt - Production based accounts per sector D_cba_reg.txt - Consumption based accounts per region D_pba_reg.txt - Production based accounts per region D_imp_reg.txt - Import accounts per region D_exp_reg.txt - Export accounts per region unit.txt - Absolute units of the stressor and impacts The unit of the coefficient data M and S are given be the unit of the satellite account per unit of the economic core (e.g. kg CO2eq/Million Euro) """
#set loop through all years for i inrange(1995,2023): #取不到2023,只到2022 print(i) #set loop for products (pxp) and sectors (ixi) for i1 inrange(0,2): j = v1[i1] #set directory for specific items in raw EXIOBASE 3.8.1 files Directory = Dir+"IOT_"+str(i)+"_"+str(j)+"//" #---------------------extracting final demand matrix Y------------------------- Path_Y = Directory + 'Y.txt' MRIO_Y = pd.read_csv(Path_Y, sep = '\t', header=0, encoding='iso-8859-1', low_memory=False) # standard UTF-8 encoding raises error MRIO_Y #print(list(MRIO_Y))
#get country list MRIO_Country = [list(MRIO_Y)[i] for i in np.arange(2,339,7)] # 生成一个从2开始,到338结束,步长为7的整数序列。这意味着我们从list(MRIO_Y)中选取了索引为2, 9, 16, ..., 338的元素。就是取到地区名称啦,其实地区名称也可以直接从exiobase论文附件找到 #print(MRIO_Country)
#make matrix Y MRIO_Y = MRIO_Y.values[2::,2::] MRIO_Y = MRIO_Y.astype('float') MRIO_Y.shape
#---------------------inversing A matrix to get L matrix------------------------- if i1 == 0: I = np.identity(7987) else: I = np.identity(9800) MRIO_L = np.linalg.inv(I-MRIO_A) MRIO_L.shape
#---------------------building the emission intensity matrix S------------------------- MRIO_X = MRIO_L.dot(MRIO_Y.sum(axis = 1)) MRIO_X MRIO_X.shape MRIO_S = np.zeros(MRIO_F.shape) for m inrange(0,MRIO_A.shape[0]): if MRIO_X[m] > 1: # Threshold for sector output: 1 MEUR MRIO_S[:,m] = MRIO_F[:,m] / MRIO_X[m] MRIO_S.shape